Least squares is one of those things that seems relatively simple once you first look at it (perhaps also because most linear algebra texts relegate it to nothing more than a page or two on their textbooks), but has surprisingly powerful implications that are quite nice, and, most importantly, that are easily computable.
If you're interested in looking at the results first, I'd recommend skipping the following section and going immediately to the next one, which shows the application.
So, let's dive right in!
Vanilla least squares
The usual least-squares many of us have heard of is a problem of the form
:$\min_x \,\,\lVert Ax - b \lVert^2 $
where I define to be the usual Euclidean norm (and $y^T$ denotes the transpose of ). This problem has a unique solution provided that is full-rank (i.e. has independent columns), and therefore that is invertible.^sq-invertible This is true since the problem above is convex (e.g. any local minimum, if it exists, corresponds to the global minimum^convex-global-min), coercive (the function diverges to infinity, and therefore has a local minimum) and differentiable such that
or that, after rearranging the above equation,
This equation is called the normal equation, which has a unique solution for since we said is invertible. In other words, we can write down the (surprisingly, less useful) equation for
A simple example of direct least squares can be found on the previous post, but that's nowhere as interesting as an actual example, using some images, presented below. First to show the presented example is possible, I should note that this formalism can be immediately extended to cover a (multi-)objective problem of the form, for
by noting that (say, with two variables, though the idea extends to any number of objectives), we can pull the into the inside of the norm and observing that
So we can rewrite the above multi-objective problem as
Where the new matrices above are defined as the 'stacked' (appended) matrix of and the 'stacked' vector . Or, defining
and
we have the equivalent problem
which we can solve by the same means as before.
This 'extension' now allows us to solve a large amount of problems (even equality-constrained ones! For example, say corresponds to an equality constraint, then we can send , which, if possible, sends that particular term to zero^eq-constraint), including the image reconstruction problem that will be presented below. Yes, there are better methods, but I can't think of many that can be written in about 4 lines of Python with only a linear-algebra library (not counting loading and saving, of course 😉).
Image de-blurring with LS
Let's say we are given a blurred image, represented by some vector with, say, a gaussian blur operator given by (which can be represented as a matrix). Usually, we'd want to minimize a problem of the form
where is the reconstructed image. In other words, we want the image such that applying a gaussian blur to yields the closest possible image to . E.g. we really want something of the form
Writing this out is a bit of a pain, but it's made a bit easier by noting that convolution with a 2D gaussian kernel is separable into two convolutions of 1D (e.g. convolve the image with the up-down filter, and do the same with the left-right) and by use of the Kronecker product to write out the individual matrices.^kronecker-conv The final is therefore the product of each of the convolutions. Just to show the comparison, here's the initial image, taken from Wikipedia
{kind=link}
<img src="/images/constrained-ls-intro/initial_image.png" class="insert"> Original greyscale image
and here's the image, blurred with a 2D gaussian kernel of size 5, with
<img src="/images/constrained-ls-intro/blurred_image.png" class="insert"> Blurred greyscale image. The vignetting comes from edge effects.
The kernel, for context, looks like:
<img src="/images/constrained-ls-intro/gaussian_kernel.png" class="insert"> 2D Gaussian Kernel with
Solving the problem, as given before, yields the final (almost identical) image:
<img src="/images/constrained-ls-intro/reconstructed_image.png" class="insert"> The magical reconstructed image!
Which was nothing but solving a simple least squares problem (as we saw above)!
Now, you might say, "why are we going through all of this trouble to write this problem as a least-squares problem, when we can just take the FFT of the image and the gaussian and divide the former by the latter? Isn't convolution just multiplication in the Fourier domain?"
And I would usually agree!
Except for one problem: while we may know the gaussian blurring operator on artificial images that we actively blur, the blurring operator that we provide for real images may not be fully representative of what's really happening! By that I mean, if the real blurring operator is given by , it could be that our guess is far away from , perhaps because of some non-linear effects, or random noise, or whatever.
That is, we know what photos, in general, look like: they're usually pretty smooth and have relatively few edges. In other words, the variations and displacements aren't large almost everywhere in most images. This is where the multi-objective form of least-squares comes in handy—we can add a secondary (or third, etc) objective that allows us to specify how smooth the actual image should be!
How do we do this, you ask? Well, let's consider the gradient at every point. If the gradient is large, then we've met an edge since there's a large color variation between one pixel and its neighbour, similarly, if the gradient is small at that point, the image is relatively smooth at that point.
So, how about specifying that the sum of the norms of the gradients at every point be small?^heat-diffusion That is, we want the gradients to all be relatively small (minus those at edges, of course!), with some parameter that we can tune. In other words, let be the difference matrix between pixel and pixel (e.g. if our image is then , and, similarly, let be the difference matrix between pixel and .^derivative-mat Then our final objective is of the form
where is our 'smoothness' parameter. Note that, if we send then we really care that our image is 'infinitely smooth' (what would that look like?^smooth-image), while if we send it to zero, we care that the reconstruction from the (possibly not great) approximation of is really good. Now, let's compare the two methods with a slightly corrupted image:
<img src="/images/constrained-ls-intro/corruptedblurredimage.png" class="insert"> The corrupted, blurred image we feed into the algorithm
<img src="/images/constrained-ls-intro/initial_image.png" class="insert"> Original greyscale image (again, for comparison)
<img src="/images/constrained-ls-intro/smoothedcorruptedreconstructedimagel=1e-07.png" class="insert"> Reconstruction with
<img src="/images/constrained-ls-intro/corruptedreconstructedimage.png" class="insert"> Reconstruction with original method
Though the normalized one has slightly larger grains, note that, unlike the original, the contrast isn't as heavily lost and the edges, etc, are quite a bit sharper.
We can also toy a bit with the parameter, to get some intuition as to what all happens:
<img src="/images/constrained-ls-intro/smoothedcorruptedreconstructedimagel=0.001.png" class="insert"> Reconstruction with
<img src="/images/constrained-ls-intro/smoothedcorruptedreconstructedimagel=1e-05.png" class="insert"> Reconstruction with
<img src="/images/constrained-ls-intro/smoothedcorruptedreconstructedimagel=1e-10.png" class="insert"> Reconstruction with
Of course, as we make large, note that the image becomes quite blurry (e.g. 'smoother'), and as we send to be very small, we end up with the same solution as the original problem, since we're saying that we care very little about the smoothness and much more about the reconstruction approximation.
To that end, one could think of many more ways of characterizing a 'natural' image (say, if we know what some colors should look like, what is our usual contrast, etc.), all of which will yield successively better results, but I'll leave with saying that LS, though relatively simple, is quite a powerful method for many cases. In particular, I'll cover fully-constrained LS (in a more theoretical post) in the future, but with an application to path-planning.
Hopefully this was enough to convince you that even simple optimization methods are pretty useful! But if I didn't do my job, maybe you'll have to read some future posts. ;)
If you'd like, the complete code for this post can be found here.
A nice picture usually helps with this: 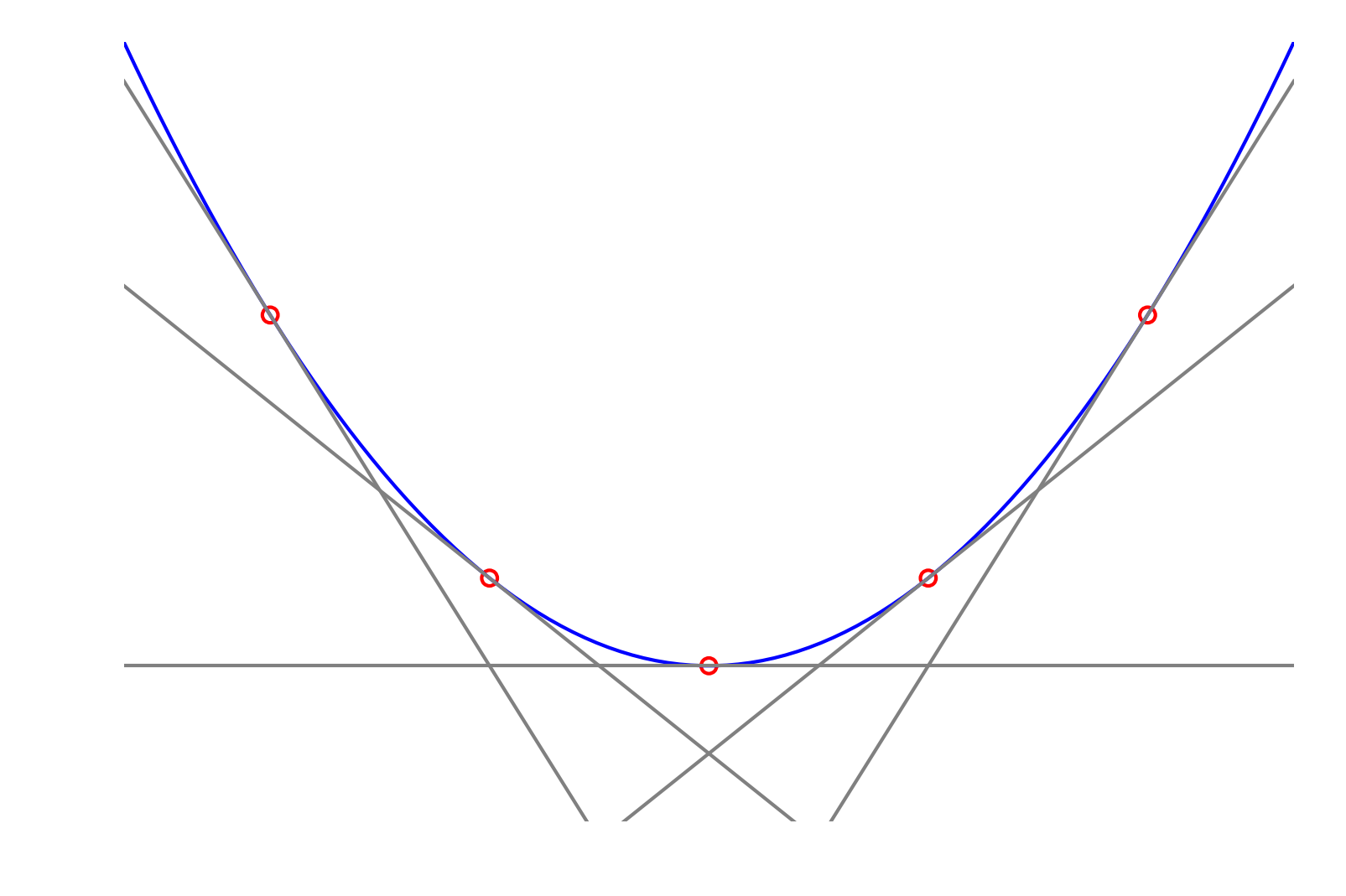
Each of the hyperplanes (which are taken at the open, red circles along the curve; the hyperplanes themselves denoted by gray lines) always lies below the graph of the function (the blue parabola). We can write this as $$ f(y)\ge (y-x)^T(\nabla f(x)) + f(x) $$ for all $x, y$. This is usually taken to be the *definition* of a convex function, so we'll take it as such here. Now, if the point $x^0$ is a local minimum, we must have $\nabla f(x^0) = 0$, this means that $$ f(y) \ge (y-x^0)^T(\underbrace{\nabla f(x^0)}_{=0}) + f(x^0) = (y-x^0)^T0 + f(x^0) = f(x^0), $$ for any $y$.
In other words, that
for any . But this is the definition of a global minimum since the point is less than any other value the function takes on! So we've proved the claim that any local minimum (in fact, more strongly, that any point with vanishing derivative) is immediately a global minimum for a convex function. This is what makes convex functions so nice!
$ G = (T\otimes I{m+n})(Im \otimes T) $
which is much simpler to compute than the horrible initial expression dealing with indices. Additionally, these expressions are sparse (e.g. the first is block-diagonal), so we can exploit that to save on both memory and processing time. For more info, I'd recommend looking at the code for this entry.
this is relatively straightforward to form using an off-diagonal matrix. Note also that this matrix is quite sparse, which saves us from very large computation. Now, we want to apply this to each row (column) of the 2D image which is in row-major form. So, we follow the same idea as before and pre (post) multiply by the identity matrix. That is, for an image
and